
Dask (biblioteca)
| Tipus | biblioteca informàtica i biblioteca Python |
|---|---|
| Basat en | NumPy, Pandas i scikit-learn |
| Versió inicial | 28 novembre 2018 |
| Versió estable | 2.30.1 (4 novembre 2020) |
| Llicència | llicència BSD |
| Característiques tècniques | |
| Sistema operatiu | multiplataforma |
| Escrit en | Python |
| Equip | |
| Creador/s | Matthew Rocklin |
| Desenvolupador(s) | Anaconda Inc |
Fonts de codi | |
| Més informació | |
| Lloc web | dask.org (anglès) |
| Stack Exchange | Etiqueta |
|
| |
Dask és una biblioteca de codi obert per a programació paral·lela i computació distribuïda en Python creada per Matthew Rocklin a finals del 2014. [1] Treballa amb l'ecosistema Python prèviament existent, permetent escalar programes a computadors multinucli i a clústers sense haver de sacrificar funcionalitats.[2]
Introducció a Dask
[modifica]Internament Dask codifica els algoritmes com a grafs dirigits en els que cada node és una tasca, i dues tasques estan enllaçades per una aresta si tenen dependències de dades. Posteriorment, un planificador de tasques executa el graf respectant les dependències de dades i explotant el paral·lelisme allà on sigui possible.
A continuació veiem un exemple que il·lustra com un còmput es pot expressar en forma de graf de tasques:
Còmput Graf generat def sum(x,y): return x+y def sqrt(x,y): return x**(1/y) def normalize(x,norm): return x/norm def mul(x,y): return x*y #Cómput que representarem com un graf mul(normalize(sum(10, 20), 100), normalize(sqrt(10, 20), 100))


Per tant, podem dividir Dask en dos grans grups funcionals:[3]
- Planificadors dinàmics de tasques que executen els grafs de tasques. Els diferents planificadors obtenen sempre resultats idèntics, però cadascun emfatitza unes certes propietats i per tant tindran rendiments diferents.
- Col·leccions de Big Data i altres API's. Les col·leccions proporcionen extensions de NumPy, Pandas i Scikit-learn que fan possible executar operacions en paral·lel sobre les estructures de dades que aquestes biblioteques proveeixen i escalarles a sistemes distribuïts.

Filosofía de Dask
[modifica]El disseny de Dask està orientat a potenciar les següents virtuts:
- Familiaritat: proveeix versions paral·lelitzades dels arrays NumPy i dels DataFrame de Pandas, deixant gairebé intacta la sintaxi característica d'aquestes biblioteques.
- Flexibilitat: proveeix una interfície d'assignació dinàmica de tasques que permet personalitzar les aplicacions i facilita la integració amb altres projectes.
- Natiu: tot el codi de Dask està escrit en Python pur.
- Rapidesa: opera amb baix overhead, baixa latència i minimitza la serialització necessària per als algoritmes numérics.
- Escalabilitat: s'executa de forma resilient en clusters de milers de nodes, però també és trivial configurar-lo per a executar codi en un únic procès.
Dask arrays
[modifica]El mòdul Array de la biblioteca Dask implementa un array paral·lel construït mitjançant diversos arrays NumPy anomenats chunks, i proveeix mètodes que actuen concurrentment sobre els diversos chunks. Gràcies a aquesta arquitectura, si distribuïm els chunks pels nodes del nostre clúster podrem treballar amb arrays que normalment no cabrien en una única memoria.[4][5]

Interfície comuna amb NumPy
[modifica]El mòdul Array suporta gran part de la interfície de NumPy, cosa que el fa molt fàcil d'aprendre per usuaris familiaritzats amb NumPy. Alguns dels mètodes més típics que implementa son
- Operacions aritmetico-matemàtiques com
+, -, *, /, exp(), log(), ... - Reduccions al llarg dels eixos com
sum(), mean(), std(), ... - Operacions d'àlgebra lineal com
svd(), qr(), solve(), solve_triangular(), lstsq(), ... - Slicing
Degut a la seva orientació cap a la computació distribuïda, els arrays Dask no implementen les operacions de NumPy que son més ineficients sobre clusters i grans volums de dades, com per exemple els algoritmes de d'ordenació.
A continuació es mostra un mateix programa escrit usant arrays Dask y NumPy. Ressaltem la gran similitud entre les dues sintaxis.
Codi amb dask.array Codi amb NumPy import dask.array as da arr = da.random.random((10000, 10000), chunks=(1000, 1000)) print(arr.sum().compute())
import NumPy as np arr = np.random.rand(10000, 10000) print(arr.sum())
Usos típics i usos contraindicats
[modifica]Els arrays de Dask son ideals per a substituir els de NumPy en problemes que involucrin grans volums de dades, doncs presenten una interfície gairebé idèntica a la de NumPy però alhora faciliten el tractament distribuït d'aquestes dades i permeten accelerar els càlculs usant diversos nuclis.
Per contra, si les dades del problema s'adapta caben a la RAM d'un computador, és millor utilitzar els arrays de NumPy, ja que Dask afegeix una capa extra de complexitat.
Dask dataframes
[modifica]El mòdul DataFrame de la biblioteca Dask implementa un dataframe paral·lel compost per diversos dataframes de la biblioteca Pandas, i proveeix mètodes que actuen concurrentment sobre els diferents dataframes de Pandas que componen el dataframe Dask. Igual que passava amb els arrays, l'arquitectura dels dataframes de Dask fa natural la computació distribuïda.[6]

Interfície comuna amb Pandas
[modifica]Els dataframes de Dask cobreixen una bona part de la API de Pandas. Algunes de les operacions més eficients son
- Operacions aritmeticològiques element a element
- Indexat i indexat lògic per files
- Proves de pertinença
- Agregacions de tipus GroupBy per files.
A continuació es mostra un mateix programa escrit usant dataframes Dask y Pandas. Ressaltem la gran similitud entre les dues sintaxis.
Codi amb dask.dataframe Codi amb Pandas import dask.dataframe as dd COLS = {0: "names_id", 1: "admin_code", 2: "name", 3: "value"} df = dd.read_csv("file.txt", sep =":", dtype= {1: "object"}, header = None) df = df.rename(columns = COLS) print(df.groupby("names_id").value.sum().compute())
import pandas as pd COLS = {0: "names_id", 1: "admin_code", 2: "name", 3: "value"} df = dd.read_csv("file.txt", sep =":", dtype= {1: "object"}, header = None) df = df.rename(columns = COLS) print(df.groupby("names_id").value.sum())
Usos típics i usos contraindicats
[modifica]Els dataframes de Dask es poden utilitzar en les mateixes situacions que els de Pandas, però son especialment útils per a manipular grans volums de dades (fins i tot si no caben en memòria), per a accelerar càlculs utilitzant diversos nuclis o per realitzar computació distribuïda amb operacions estàndards de Pandas.
Per contra, si el conjunt de dades a tractar s'adapta còmodament a la RAM del computador és millor utilitzar els dataframes de Pandas, ja que ofereixen més opcions.
Dask delayed
[modifica]Hi ha problemes que no encaixen en col·leccions predissenyades com dask.array o dask.dataframe. En aquests casos, el mòdul dask.delayed permet paral·lelitzar algoritmes de disseny propi mitjançant la creació explícita de Grafs de tasques.[7]
Les tres funcions més importants del mòdul Delayed son:[8]
delayed()- La funció delay envolta còmputs, que poden ser funcions junt amb els seus arguments d'entrada, i retorna un objecte de tipus Delayed que conté el graf de tasques necessari per a realitzar el còmput. Per exemple, per a envoltar el còmput consisten en aplicar una funció
foosobre dos arguments d'entradaaibfaríemx = dask.delayed(foo)(a,b).
visualize()- El mètode visualize actúa sobre un objecte de tipus Delayed i mostra per pantalla el graf de tasques associat.
compute()- El mètode compute actúa sobre un objecte de tipus Delayed i crida a un planificador dinàmic de tasques que l'executa aprofitant tot el paral·lelisme possible.
A continuació es mostra un exemple d'un programa Python paral·lelitzat usant el mòdul dask.delayed. El programa llegeix un graf d'un fitxer estructurat en format <ID NUM_ARESTES POSX POSY> i calcula les parelles de nodes que son més properes mútuament.
Funcions en python sobre les que s'aplica dask.delayed Graf generat ##PURE PYTHON FUNCTIONS def read_graph(file): positions= [] with open(file,'r') as hl: for x in hl.readlines()[1:]: temp = [] for y in x.split()[2:]: temp.append(float(y)) positions.append(temp) return positions def get_nearest(x,positions): minimum = 1000000 min_pos=0 actual_node = positions[x] print(actual_node) for pos,node in enumerate(positions): if pos!=x: distance = ((actual_node[0]-node[0]) **2 + (actual_node[1]-node[1])**2)**(1/2) if distance<minimum: minimum=distance min_pos=pos return min_pos def mutual(x,positions,min_pos): return True if x==get_nearest(min_pos,positions) else False def count(x,list): counter= 0 for y in list: if x==y: counter+=1 return counter/2 #Es limita el numero de nodes perque el graf sigui visualitzable NUM_NODES = 5 ##DASK CODE read_graph_da = da.delayed(read_graph)('Grafo4.txt') output = [] for x in range(NUM_NODES): min_dist_pos = da.delayed(get_nearest)(x,read_graph_da) output.append(da.delayed(mutual)(x,read_graph_da,min_dist_pos)) total_mutuals = da.delayed(count) (True,output) total_mutuals.visualize() total_mutuals.compute()
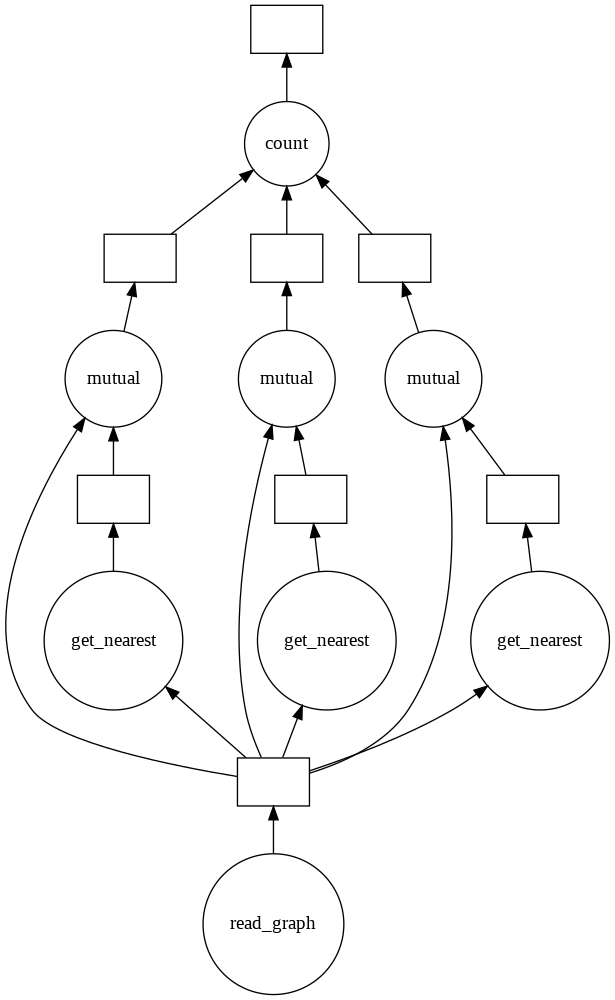

La funció delayed també es pot usar com un decorador. Per exemple, si fem
import dask
@dask.delayed
def add(x,y):
return x + y
aleshores totes les crides add(a,b) retornaran un objecte Delayed exactament igual que si haguessim fet dask.delayed(add)(a,b).
Planificadors dinàmics de tasques
[modifica]Els planificadors de tasques reben els grafs que generen col·leccions com dask.array, dask.dataframe i API's com dask.delayed i executen en paral·lel els programes que aquests grafs simbolitzen. Els diferents planificadors obtenen sempre resultats idèntics, però cadascun emfatitza unes certes propietats i per tant tindran rendiments diferents.
Els planificadors de tasques implementats son:[9]
- Local Threads
- Executa els còmputs seguint un model de paral·lelisme de threads, és a dir, executa els còmputs concurrentment utilitzant diversos fils pertanyents a un mateix procés. Introdueix molt poc overhead, però degut al GIL de Python només proveeix paral·lelisme a programes Python en els que domina el codi compilat (com per exemple el de NumPy o Pandas). Aquest planificador de tasques es el que utilitzen per defecte
dask.array,dask.dataframeidask.delayed.
- Local Processes
- Executa els còmputs seguint un model de paral·lelisme de processos, és a dir, cada tasca del graf s'executa en un procés diferent. Per tant, aquest planificador de tasques evita problemes amb el GIL i pot executar codi Python pur en paral·lel. Convé no usar aquest planificador en programes que requereixin una alta comuniació entre tasques, doncs moure dades entre processos penalitza el rendiment.
- Single Thread
- Executa totes les tasques en un mateix thread sense res de paral·lelisme. Se sol utilitzar per a debuggar.
- Distributed
- Permet executar el programa de forma distribïda, és a dir, sobre un clúster. És el planificador de tasques més modern i versàtil.
Altres mòduls i col·leccions d'interès
[modifica]Altres mòduls de Dask, amb una utilitat molt més específica, són:
- Dask bag
- Implementa operacions tipus
map,filterigroupbyen paral·lel sobre objectes genèrics de Python. És ideal per a paral·lelitzar i/o distribuir computacions simples en dades no estructurades o semiestructurades com dades de text, fitxers de registre, registres JSON o objectes Python definits per l'usuari.[10]
- Dask ML
- Mòdul dedicat a projectes de Machine Learning basat en les biblioteques Scikit-Learn, XGBoost i TensorFlow. Garanteix l'escalabilitat dels algoritmes preparant i configurant les dades d'entrada per a posteriorment utilitzar els avantatges de les llibreries ja existents.[11]
- Dask Futures
- Extensió de la biblioteca
concurrent.futuresde Python. Proveeix eines per a la computació de tasques arbitràries en temps real.[12]
Referències
[modifica]- ↑ Rocklin, Matthew. Dask: Parallel Computation with Blocked algorithms and Task Scheduling, p. 126–132. DOI 10.25080/Majora-7b98e3ed-013.
- ↑ Daniel, Jesse C. Data Science at Scale with Python and Dask. Manning Publications, 2019. ISBN 9781617295607.
- ↑ «dask.org».
- ↑ «Array — Dask 2.13.0 documentation».
- ↑ «Parallel computing with Dask — xarray 0.15.0 documentation».
- ↑ «DataFrame — Dask 2.13.0 documentation».
- ↑ «Delayed — Dask 2.13.0 documentation».
- ↑ «API — Dask 2.13.0 documentation».
- ↑ «Scheduling — Dask 2.13.0 documentation».
- ↑ «Bag — Dask 2.13.0 documentation».
- ↑ «ML — Dask 2.13.0 documentation».
- ↑ «Futures — Dask 2.13.0 documentation».
Vegeu també
[modifica]Bibliografia
[modifica]- Rocklin, Matthew. Dask: Parallel Computation with Blocked algorithms and Task Scheduling, p. 126–132. DOI 10.25080/Majora-7b98e3ed-013.
- Daniel, Jesse C. Data Science at Scale with Python and Dask. Manning Publications, 2019. ISBN 9781617295607.